Changelog
November 21
- Recently added models: gpt-4o-2024-11-20, step-2-16k, grok-vision-beta
- Qwen 2.5 Turbo Million Context Model: qwen-turbo-2024-11-01
November 7
- Compatible with Claude native SDK, v1/messages interface is now supported;
- Cache and computer usage functions for Claude native interface are not yet supported (prompt caching and computer use). We will continue to improve these features in the next two weeks.
November 5
- Added new model: claude-3-5-haiku-20241022
- Added Elon Musk's x.ai latest model grok-beta
October 23
- Added new model: claude-3-5-sonnet-20241022
October 10
OpenAI's latest caching feature is now online. This feature currently supports the following models:
- GPT-4o
- GPT-4o-mini
- o1-preview
- o1-mini
Please note, the gpt-4o-2024-05-13 version is not officially supported.
If a request hits the cache, you will be able to see the relevant cache token data in the backend logs.
For more detailed information and usage rules, please visit the OpenAI official website: OpenAI Caching Feature Details
October 3
- Reduced backend billing for the gpt-4o model, synchronized with the official pricing
- Added new models: aihubmix-Llama-3-2-90B-Vision, aihubmix-Llama-3-70B-Instruct
- Added Cohere's latest models aihubmix-command-r-08-2024, aihubmix-command-r-plus-08-2024
September 19
- Added new models: whisper-large-v3 and distil-whisper-large-v3-en
- Note: Whisper model billing is based on input seconds, but there is currently a display issue with the page pricing which will be fixed in the future. Backend billing is accurate, fully synchronized with OpenAI's official charges.
September 13
- Added models o1-mini and o1-preview; Note: These latest models require changes in input parameters. Some wrapper software may report errors if default parameters are not updated.
Important Notes
Testing shows that the 01 models do not support the following and will report errors:
- system field: 400 error
- tools field: 400 error
- image input: 400 error
- json_object output: 500 error
- structured output: 400 error
- logprobs output: 403 error
- stream output: 400 error
- o1 series: 20 RPM, 150,000,000 TPM, very low, 429 errors may occur at any time
- Others: temperature, top_p, and n are fixed at 1; presence_penalty and frequency_penalty are fixed at 0
September 10
- Added new model: mattshumer/Reflection-Llama-3.1-70B; reportedly the strongest fine-tuned version of llama3.1-70b
- Increased Claude-3 model pricing to maintain stable supply, currently 10% more expensive than directly using the official API; prices will gradually decrease in the future.
- Enhanced concurrent capabilities of OpenAI series models, theoretically supporting unlimited concurrency.
August 11
- Added new models: Phi3medium128k, ahm-Phi-3-medium-4k, ahm-Phi-3-small-128k
- Improved stability of Llama-related models
- Further optimized compatibility of Claude models
August 7
- Added OpenAI's newly updated 4o version gpt-4o-2024-08-06, see https://platform.openai.com/docs/guides/structured-outputs
- Added Google's latest model: gemini-1.5-pro-exp-0801
August 4
- Added online direct payment recharge
- Fixed Claude multi-turn conversation format error: 1. messages: roles must alternate between "user" and "assistant", but found multiple "user" roles in a row;
- Optimized the index issue when using function features of Claude models
- The backup server https://orisound.cn will be fully decommissioned on September 7; please switch to the main server https://aihubmix.com or backup server https://api.aihubmix.com
July 27
- Added support for Mistral Large 2, model name: Mistral-large-2407 or aihubmix-Mistral-large-2407;
- System optimization
July 24
- Added latest llama-3.1 models llama-3.1-405b-instruct, llama-3.1-70b-versatile, and llama-3.1-8b-instant; feel free to try them out.
July 20
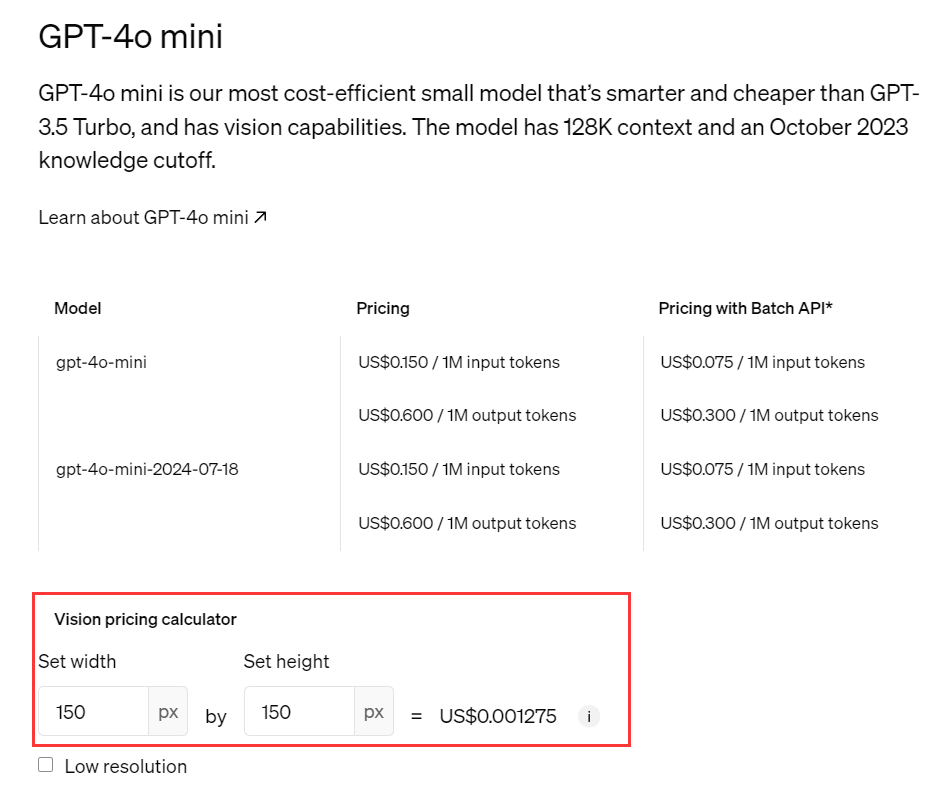
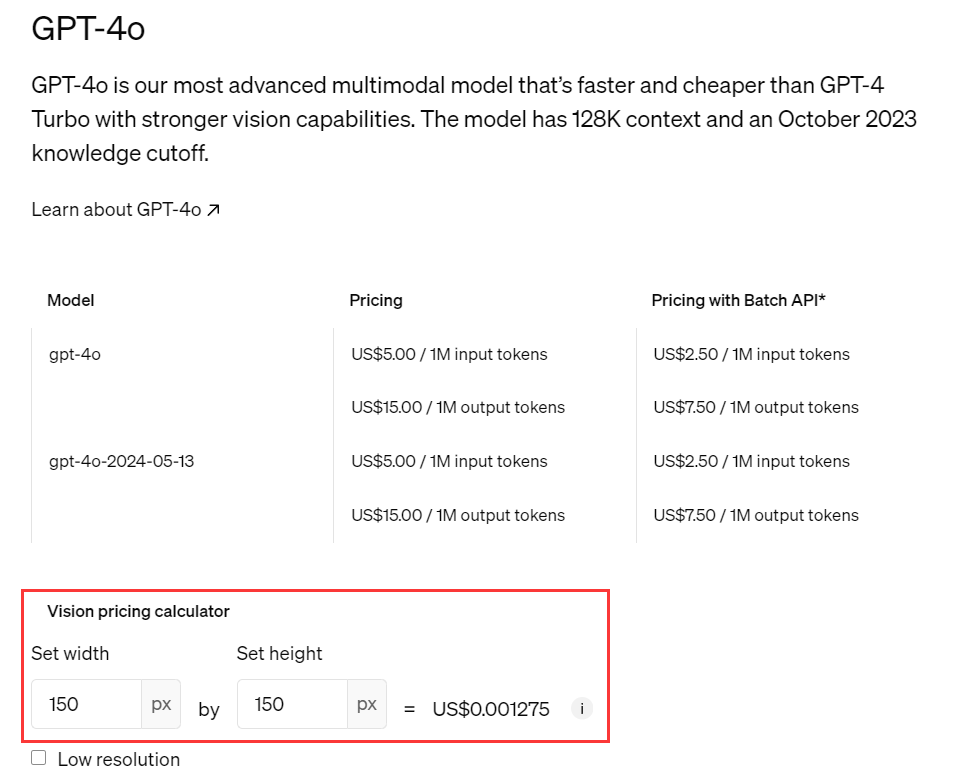
- Fixed pricing calculation issue for gpt-4o-mini model. Details are as follows: Text input price: The price for text input of OpenAI's official gpt-4o-mini model is only 1/33 of the gpt-4o model price. Image input price: The price for image input of OpenAI's official gpt-4o-mini model is equal to the gpt-4o model price.
- To ensure accuracy in price calculation, we multiply the token count for image input of the gpt-4o-mini model by 33 times to align with the official price.
- More details can be found in OpenAI Official Pricing
July 19
- Added support for gpt-4o-mini model, backend billing synchronized with official
July 15 Announcement
- Supports the official API parameter include_usage, passing in parameters can return usage in stream mode, details see Official Documentation
July 14 Announcement
- New version of nextweb added support for calling non-OpenAI models Call Non-OpenAI Models on Our Site
- Added backend billing for Alibaba Qwen models, overall cost is about 10% higher than calling Alibaba Cloud official
- Optimized Azure OpenAI output compatibility with OpenAI interface
- Supports Claude-3's tool calling
- Added many new models, see Settings for available models
July 3 Announcement
- Overall backend interface optimized
- Each log request record now shows the model unit price at the time of the request
- Added model and pricing page Model/Pricing
June 20 Announcement
- The latest claude-3-5-sonnet-20240620 is now supported, for usage instructions see How to Call Non-OpenAI Models on Our Site
June 18 Announcement
- The backend log page now supports downloading usage request records
June 16 Announcement
- Reduced the probability of randomly hitting Azure OpenAI, now it's almost negligible
June 13 Announcement
- Lowered fees for Claude-3 related models (Claude 3 Haiku, Claude 3 Sonnet, Claude 3 Opus) to align with official backend charges; thus, the current retail price for using our API is approximately 14% off the official price.
June 10 Announcement
- Overall service architecture upgrade, all servers and data migrated to Microsoft Azure;
- In the future, I will conduct secondary deep development and optimization based on the open-source version of one API (we have already obtained a commercial license for the one API project through sponsorship)
- Log data is too large (over 100 million request logs) and cannot be migrated temporarily; please contact customer service for previous log queries
- Optimized token billing for gpt-4o, tokenizer cI100k_base changed to 0200k_base, previously gpt-4 series used cI100k_base; this results in a decrease in token count for streaming requests in Chinese, Korean, and Japanese.
June 8 Announcement
- Added Alibaba's latest open-source model Qinwen2
- alibaba/Qwen2-7B-Instruct, alibaba/Qwen2-57B-A14B-Instruct, alibaba/Qwen2-72B-Instruct
May 20 Announcement
- Added new model gemini-1.5-flash
- Added new model gpt-4o
- Error accessing recharge page in Jiangsu region due to telecom hijacking of recharge domain, please contact customer service for recharge.
- Added llama3 (llama3-70b-8192, llama3-8b-8192) gemini-1.5-pro, command-r, command-r-plus, feel free to try
- Claude-3 model supply restored; we are currently connecting to Claude-3 endpoints deployed on AWS and Google Cloud.
- To cover server costs and team expenses, Claude-3 model and price backend billing is 10% more expensive than the official
- If call volume increases, prices will gradually decrease to around 5% or even lower,
- Current concurrency needs testing and will apply for higher concurrent calls as usage increases.